主题
缓存设计
常见缓存技术
- MemCache:一个高性能的分布式内存对象缓存系统,用于动态web应用以减轻数据库负载。Memcache在内存里维护一个统一的巨大的hash表,数据存在该表中。
- Redis:一个开源的使用C语言编写、可持久化的key-value数据库,支持多种数据类型,并提供多种语言的API。
- Squid:一个高性能的代理缓存服务器,支持FTP、gopher、HTTP和HTTPS协议。
| MemCache | Redis | |
|---|---|---|
| 数据类型 | 简单KV结构 | 丰富数据类型 |
| 持久性 | 不支持 | 支持 |
| 分布式存储 | 客户端哈希分片/一致性哈希 | 主从、哨兵、集群 |
| 多线程支持 | 支持 | 有限支持(5.0版本之前不支持) |
| 内存管理 | 私有内存池/内存池 | 无 |
| 事务支持 | 不支持 | 有限支持 |
| 数据容灾 | 不支持,不能做数据恢复 | 支持 |
目前 Redis 为主流缓存解决方案。
缓存和数据库的一致性问题
组合一:先更新缓存,再更新数据库
假设在更新数据库时失败了需要回滚,那缓存的数据要如何还原呢?Redis是不支持事务回滚的,除非采用手工回滚的方式,先保存原有数据,再将缓存更新为原来的数据。但这在多线程情况下也会有问题。
| A | B |
|---|---|
| 更新缓存值 a->b | |
| 更新缓存值 b->c | |
| 更新数据库值为 c | |
| 更新数据库值(c->b)时失败,回滚为c | |
| 缓存如何回滚? |
理论上,线程A应该将缓存手动回滚到c,但是线程A无法获得c这个值。这种方案就是典型的事务隔离级别的场景,要额外处理逻辑,成本太大。因此不推荐使用。
组合二:先删除缓存,再更新数据库
| A | B |
|---|---|
| 删除缓存 | |
| 读取缓存,无数据 | |
| 读取数据库旧值a更新到缓存 | |
| 更新数据库值为b |
数据库中的值为b,但缓存中的值为a,出现数据不一致的情况。如果让A线程给Key加锁,因为写操作特别耗时,会导致大量的读请求卡在锁中。此外,先删除缓存,还要注意缓存击穿的问题。
组合三:先更新数据库,再更新缓存
假设更新数据库成功,但更新缓存失败了。因为缓存不是主流程,所以不会存在回滚。此时一般的做法是重试,但重试机制如果存在延时还是会出现不一致的情况。
此外,对于并发操作还是有问题:
| A | B |
|---|---|
| 更新数据库值为 a | |
| 更新数据库值为 b | |
| 更新缓存值为 b | |
| 更新缓存值为 a |
数据库中的值为b,但缓存中的值为a,出现数据不一致的情况。
组合四:先更新数据库,再删除缓存
相比于组合三,删除缓存比更新容易多,出现删除失败的概率较低,如果失败,可以重试。对于并发操作,由于都是删除操作,先后顺序也就不重要了。组合四相对较好,但还有个小缺陷:
| A | B |
|---|---|
| 更新数据库值 a->b | |
| 读取缓存值 a | |
| 删除缓存值 a |
线程A在更新数据库之后、删除缓存之前,线程B读取缓存值,获取的就是旧值。
删除缓存失败的重试策略:
- 最简单的就是 try...catch...方式,在 catch 中重试一次。
- 异步线程不断重试,但基本上重试多次也还是会失败。
- 复杂一点是用异步线程将重试推送到 MQ 中。
- 写 MQ 还是可能会遇到网络问题,可以使用基于 Binlog 的异步更新策略。
大部分情况下,没必要大动干戈,使用最简单的策略即可,重试的延时越长,读脏数据的可能性越大。
组合五:先删除缓存,更新数据库,再删除缓存
| A | B | C |
|---|---|---|
| 删除缓存 | ||
| 读缓存,无数据 | ||
| 读取数据库旧值a并写入缓存(此时缓存值为a) | ||
| 更新数据库值为b | ||
| 读缓存,获取旧值a | ||
| 删除缓存 |
可以看出,组合五出现问题的概率更低,需要刚好有3个线程配合才会出现问题。此方案第二次删除缓存之前,通常延迟一段时间,为了确保线程B在这之前把数据库的旧值写入到缓存,否则线程A第二次删除缓存之后,线程B又会把数据库的旧值写入缓存。具体延时多长时间,可以统计线程读数据和写缓存的操作时间,以此为基础估算。因此,组合五也称延时双删。
小结
综上,不管哪种组合,它们都有读到脏数据的可能,只不过概率不同。它们只能保证数据的最终一致性,无法保证数据的强一致性。
根据 CAP 理论,一个业务系统只能在一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)中最多满足两个。使用缓存和数据库,相当于实现了P,因此系统只能是一个:
- CP系统:保证强一致性,通过 Paxos、Raft 等一致性协议是可以做到的,但可能并非业务侧想要的,因为牺牲了可用性(主要是性能问题)。
- AP系统:保证可用性,但是牺牲强一致性(只做最终一致性)。
如果实现CP系统,系统的可用性(性能)会受到比较大的影响。对于大多数系统而言,引入缓存只是为了提升读取的性能,如果最终结果反而牺牲可用性(性能),那就本末倒置了。 因此通常业务系统不会选择CP,不去强求强一致性。
优先考虑组合三、组合四或组合五,具体根据业务场景来选择。如果是只读缓存,建议使用组合四——先更新数据库,再删除缓存。因为先删除缓存可能会带来缓存击穿问题。
缓存常见问题
缓存穿透
用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
解决方案:
- 限制恶意访问某些不存在数据的请求。
- 如果查询结果为空,直接设置一个默认值放到缓存,这样第二次到缓存中获取就有值了。设置一个不超过5分钟的过期时间,以便能正常更新缓存。
- 使用布隆过滤器。将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截,从而避免对底层存储系统的查询压力。
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。可以用于检索一个元素是否在一个集合中。
优点:
- 占用内存小。
- 查询效率高。
- 不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
缺点:
- 有一定的误判率:如果判断出元素不在集合中,那么一定不在;但如果判断出元素在集合中,元素不一定在集合中。
- 一般情况下不能从布隆过滤器中删除元素。
- 不能获取元素本身。
缓存击穿
某个热点数据在缓存中没有但数据库中有,这时用户并发访问此热点数据,同时读缓存没读到数据,又同时去数据库取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
- 设置热点数据永不过期,由后台异步更新缓存。
- 在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间。
- 加互斥锁,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。。
缓存雪崩
当大量缓存数据在同一时间过期(失效)或者 缓存服务器故障宕机时,如果此时有大量的用户请求,都无法在缓存中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。和缓存击穿不同的是,缓存击穿指并发查同一条数据(热点数据),缓存雪崩是不同数据都过期了。
解决方案:
针对大量缓存数据同时过期的情况:
- 使用锁或队列:保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。
- 为key设置不同的过期时间:在固定的一个时间基础上,再加上一个随机时间作为缓存失效时间。
- 二级缓存:设置一个有时间限制的缓存和一个无时间限制的缓存。避免大规模访问数据库。
针对缓存服务器故障宕机的情况:
- 服务熔断或请求限流:服务熔断即暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,但这会导致业务不可用。为了减少对业务的影响,我们可以启用请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到服务器恢复正常并把缓存预热完后,再解除请求限流的机制。
- 构件缓存服务高可用集群。
Redis
Redis数据类型
| 数据类型 | 特点 | 常见使用场景 |
|---|---|---|
| String | 存储二进制,任何数据类型,最大512M | 缓存;常规计数(如访问次数、点赞、转发、库存数量等);分布式锁;共享session |
| List | 简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。 | 消息队列 |
| Hash | 无序字典,一个key对应一个对象 | 缓存对象 |
| Set | 无序集合;支持交/并/差集操作 | 共同关注;独立IP;标签 |
| ZSet | 有序集合,自带按权重排序效果 | 排行榜 |
| BitMap | 位图,是一串连续的二进制数组(0和1),可以通过偏移量定位元素。 | 二值状态统计场景:签到统计;判断用户登入态;连续签到用户总数 |
| HyperLogLog | 统计基数。基于概率,存在标准误差0.81% | 百万计网页UV计数 |
| GEO | 用于存储地理位置信息 | 经纬度范围查询 |
| Stream | 专门设计的消息队列(5.0新增) |
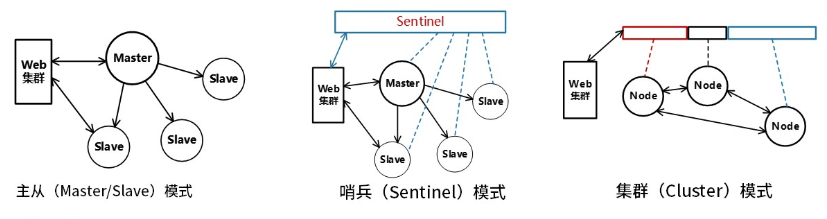
Redis分布式存储方案
| 分布式存储方案 | 核心特点 |
|---|---|
| 主从模式 | 一主多从,故障时手动切换 |
| 哨兵模式 | 有哨兵的一主多从,主节点故障自动选择新的主节点 |
| 集群模式 | 分节点对等集群,分slots,不同slots的信息存储在不同节点 |
Redis集群分片
Redis分片集群将整个数据库默认划分为16384个哈希槽,每个键通过哈希算法(如 CRC16(key) % 16384)映射到一个槽位。每个节点负责一定数量的槽位,确保数据均匀分布。客户端通过计算键的哈希槽号,直接定位到对应的节点。通常,每个主节点应该至少有一个从节点,当主节点接收到写操作时,它会将写操作同步到所有的从节点上,从而实现数据的备份和冗余。读操作可以在主节点和从节点上进行,以提高读取性能。
| 分片模式 | 核心特点 |
|---|---|
| 客户端模式 | 在客户端通过key的hash值对应到不同的服务器 |
| 中间件模式 | 在应用软件和Redis中间由中间件实现服务到Redis节点的路由分派 |
| 客户端服务端协作模式 | 客户端可采用一致性哈希,服务端提供节点的重定向到slot上。 不同的slot对应到不同服务器 |
分片策略见数据库分库分表:分片策略
Redis过期删除策略
Redis过期删除策略:惰性删除 + 定期删除
Redis内存淘汰策略
| 策略 | 描述 |
|---|---|
| *-random | 随机淘汰键值 |
| volatile-ttl | 优先淘汰更早过期(ttl值越小)的键值 |
| *-lru | 优先淘汰最近未使用的键值 |
| *-lfu | 优先淘汰最少使用的键值 |
Redis持久化
Redis的持久化主要有两种方式:RDB和AOF。
- RDB:指定时间间隔将内存中的全量数据进行快照存储。(传统数据库快照的思想)
- AOF:把每条改变数据集的命令追加到AOF文件末尾,出问题时,重新执行AOF文件的命令来重建数据库。(传统数据库日志的思想)
| 对比维度 | RDB | AOF |
|---|---|---|
| 备份量 | 重量级的全量备份 | 轻量级的增量备份,一次只保存一个修改命令 |
| 保存间隔时间 | 长 | 短(默认1秒) |
| 还原速度 | 快 | 慢 |
| 阻塞情况 | 同步方式(save)阻塞; 异步(bgsave)方式和自动不阻塞 | 不阻塞 |
| 安全性 | 低,容易丢失数据 | 高,根据策略决定 |
Redis执行Lua能保证原子性吗?
区别于关系型数据库,Redis 中执行 Lua 脚本的原子性是指:Lua 脚本需要作为一个整体执行且不被其他事务打断,至于 Lua 脚本里面的命令是否必须全部成功,或者全部失败,并不要求。
在 Lua 中调用 Redis 命令:
- redis.call():当命令执行出错时,会阻断整个脚本执行,并将错误信息返回给客户端。
- redis.pcall():当命令执行出错时,不会阻断脚本的执行,而是内部捕获错误,并继续执行后续的命令。
以 Redis 单机部署为例,当客户端向服务器发送一段带有 Lua 脚本的请求时,Redis 会把该 Lua 脚本当作一个整体,将 Lua 脚本加载到一个脚本缓存中,因为 Redis 读写命令是单线程操作,因此,Lua 脚本的读写在 Redis 服务器上可以简单理解为队列机制,所有的 Lua 脚本会按照进入顺序放入队列中,然后串行进行读写,这样就保证了原子性。
单机部署和主从部署都能保证原子性。但对于集群部署:如果 Lua 脚本中操作的 Key 是同一个,则能保证原子性;如果操作 不同的 Key,不一定能保证原子性。因为可能被 hash 到不同的slot。